论文地址:https://arxiv.org/pdf/2403.12173
# 摘要
将非结构化文本转化为由有用的类别标签组织的结构化且有意义的形式,是文本挖掘中用于下游分析和应用的基础步骤。然而,大多数现有的生成标签分类法和构建基于文本的标签分类器的方法仍严重依赖领域专业知识和人工整理,这使得该过程成本高昂且耗时。当标签空间定义不明确且缺乏大规模数据标注时,这一挑战尤为突出。
在本文中,我们利用大型语言模型(LLMs)解决这些挑战,其基于提示词的接口便于大规模伪标签的生成和使用。我们提出了 TnT-LLM,这是一个两阶段框架,它利用 LLMs 在任何给定的用例中,以最少的人工干预实现端到端的标签生成和分配过程的自动化。在第一阶段,我们引入了一种零样本、多阶段推理方法,使 LLMs 能够迭代生成和优化标签分类法。在第二阶段,LLMs 被用作数据标注器来生成训练样本,以便能够可靠地构建、部署轻量级有监督分类器并大规模应用。
我们将 TnT-LLM 应用于必应 Copilot(前身为必应聊天)的用户意图和对话领域分析,这是一款开放域基于对话的搜索引擎。使用人工和自动评估指标进行的大量实验表明,与最先进的基线方法相比,TnT-LLM 生成的标签分类法更准确、更相关,并且在大规模分类任务中实现了准确性和效率之间的良好平衡。我们还分享了在现实应用中使用 LLMs 进行大规模文本挖掘的挑战与机遇方面的实践经验和见解。
# 框架介绍
文本挖掘中的两个核心且相关的任务:taxonomy generation(分类法生成)与 text classification(文本分类)。
分类法生成,即生成一组结构化规范标签,比如 “计算机研究领域”,其标签有人工智能、软件工程、操作系统等。文本分类,即根据语料库的实例,对其进行标签的标注。
本文介绍的 TnT-LLM 是一个端到端的两阶段框架,实现了分类法生成与文本分类两个阶段的自动化。
# 阶段一:分类法生成
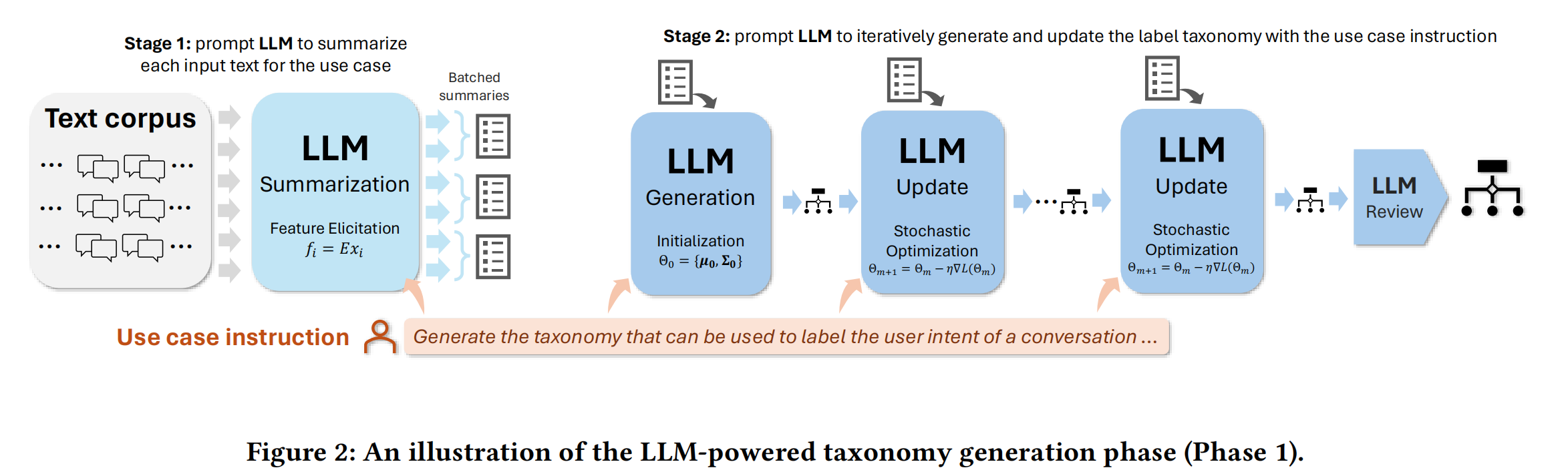
# Stage 1: Summarization(摘要)
使用 LLM 对所有文档进行摘要生成,从而规范化样本并提取出其最突出的信息,减小输入文档的规模与可变性。
# Stage 2: Taxonomy Creation, Update, and Review(分类法创建、更新与审核)
参考了随机梯度下降(SGD)的思想。
个人认为,这里是参考了 SGD 随机探路更新,直到找到一个最佳点的思路。
将步骤一生成的摘要划分为大小相等的小批次数据(后面的实验里用的是 200 条数据一个小批次),然后,使用三种零样本大语言模型推理提示来处理这些小批次数据。
- 第一种是初始生成 prompt,以第一组小批次数据作为输入,生成初始的标签分类法。
- 第二种是分类法更新 prompt,它使用新的小批次数据迭代更新现有的标签分类法。
执行三项主要任务:① 在新数据上评估现有的分类法 ② 根据评估结果找出问题并给出建议 ③相应地修改分类法。 - 最后一种是审核评估 prompt。在分类法更新指定次数后,应用审核评估来检查分类法的格式与质量,输出最终结果。
层次结构的生成:若想生成多层次分类法,在第一轮分类生成之后,可以针对已分类样本的组合重新运行 Stage 2,从而创建新的、更细粒度的层级。
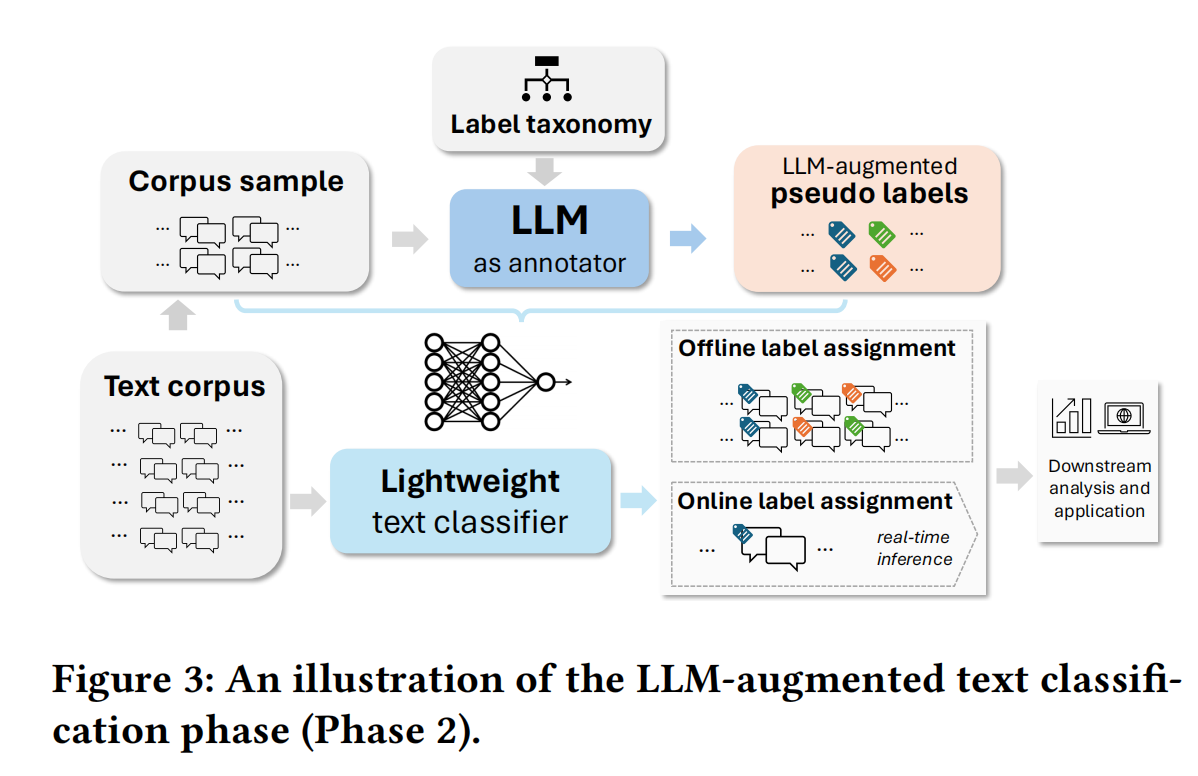
# 阶段二:大语言模型增强的文本分类
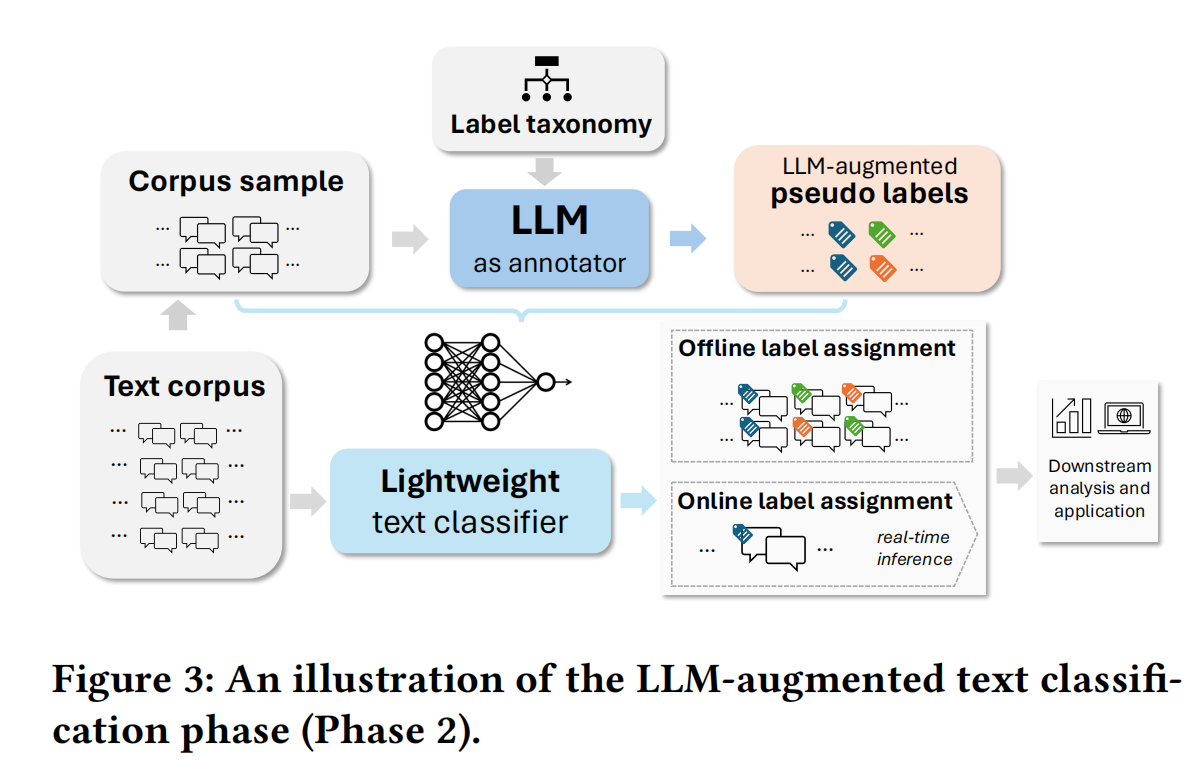
利用大语言模型首先来获得一个 “伪标签” 语料库,接着使用该语料库进行监督学习,训练一个轻量级分类器。
具体来说,首先促使 LLM 在一个中到大型规模的语料库样本上推断主要标签(用于多类分类任务)和所有适用标签(用于多标签分类任务)。创建一个具有代表性的训练数据集,然后使用该数据集构建轻量级分类器。使用到的三种分类器:逻辑回归、梯度提升的 LightGBM 以及两层多层感知器(MLP)。
# 评估方法
本框架自定义了一套评估方法。其主要旨在结合基于大语言模型的评估与小语料库上的人工评估指标。
# 第一阶段(分类法生成)评估
三个角度:分类法覆盖率(Taxonomy Coverage),标签准确率(Tabel Accuracy),与用例说明的相关性(Relevance to Use-case Instruction)。
- 分类法覆盖率:衡量分类法的全面性。在标签中添加了 “其他” 或 “未定义” 类别,该类别下数据点比例越低,代表分类法覆盖率越高。
- 标签准确率:即判断标签对数据点的反映程度。比如给出一个库,贴上了 “人工智能” 的标签,你需要判断这是否准确。
- 与用例说明的相关性:衡量生成的标签分类法与用例说明的相关程度。比如需要生成计算机科学领域分类的标签,结果生成了一个 “历史” 的标签,这肯定不相关。
# 分类法质量评估
在本文实验过程中,对于评估分类法质量,采用了多人人工评估与 LLM 评估的方式。如下图:
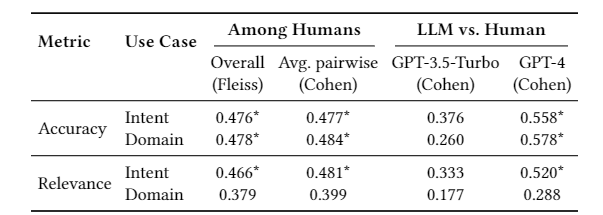
该表的核心目的:评估 “不同评估者对‘标签分类法质量’的判断是否一致”,以此验证标签分类法本身是否可靠,以及评估过程是否可信。
表 1 通过计算 “一致性指标(Kappa 值)”,告诉我们:
- 人类对标签质量的判断是否统一(以此看任务是否清晰);
- LLM(尤其是 GPT-4)能否替代人类做评估(如果 LLM 和人类判断一致,就可以用 LLM 高效大规模评估)。
# 准确率与相关性对比评估
对比组:先使用基于嵌入的聚类方法生成聚类,再从每个聚类中抽取对话让 LLM 根据对话生成这个聚类的标签,这样生成一个标签分类法。
进行对比评估,发现使用 GPT-4 的 TnT-LLM 框架所得到的分类法在准确率与相关性上最优。
# 第二阶段(文本分类)评估
对小规模语料库样本进行人工标注与 LLM 标注,以人工标注的结果为基准计算分类器分类的各项指标(准确率、F1 值等)。这些指标用于评估分类器在语料库的一个小子集上与人类偏好的契合度。
然后,对更大规模的语料库进行 LLM 标注,将该标注结果作为基准计算分类器分类的相同的指标。这些指标能从不同方面对分类器在大规模语料库上的性能进行全面诊断。
对比组:直接使用 GPT-4 进行标注(即小规模语料库的 LLM 标注)。
需要注意的是:其主要目标是对比基于 LLM 标签训练的蒸馏轻量分类器与完整 LLM 分类器之间的性能差异;目的是相较于成本更高但可能更强大的 LLM,实现准确性与效率之间的良好平衡。
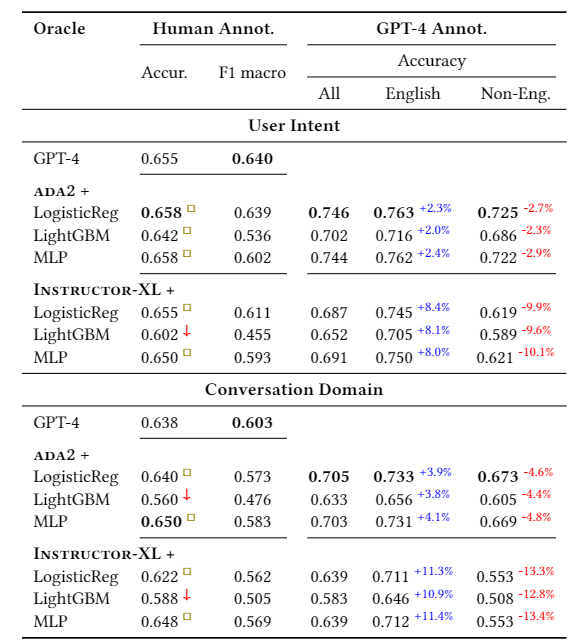
实验结果如上。在人工标注的数据集上,可以看到有几种分类器的效果已经优于 GPT-4 的直接标注分类。逻辑回归效果最好,而 LightGBM 效果最差。
在 GPT-4 大规模标注的数据集上,则考察了语言对于标注结果的影响。非英语的性能显然低于英语对话。
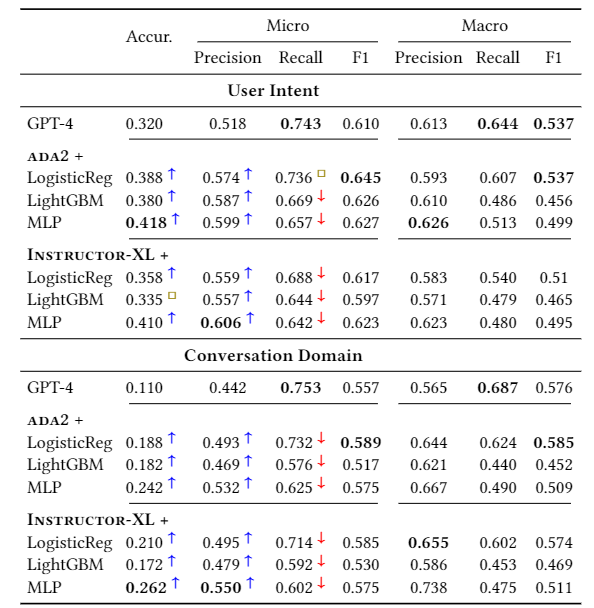
此外还进行了多标签分类任务(即一个样例可能不止有一个标签),研究发现与 GPT-4 相比,分类器以牺牲一些召回率为代价实现了更高的精度。
# 数据集
实验中使用的数据集均来自 Bing Copilot(前身为 Bing Chat) 的人机对话记录,属于开放域对话式搜索引擎的真实用户交互数据。
核心子数据集包括:
- BingChat-Phase1-S-Eng
- BingChat-Phase1-L-Multi
- BingChat-Phase2-S-Eng
- BingChat-Phase2-L-Multi
# (1)BingChat-Phase1-S-Eng
- 特性:小规模(“S” 代表 Small)英文(“Eng” 代表 English)数据集。
- 用途:
- 用于标签分类法的质量评估(人工评估),如 Table 1(评估者间一致性)和图 4a(人类对标签准确性 / 相关性的评分)。
- 作为验证集,用于聚类算法的最优结果选择(如通过轮廓系数筛选最佳聚类结果)。
- 关键作用:提供人工标注的 “标准答案”(oracle),验证标签分类法的可靠性和评估方法的有效性。
# (2)BingChat-Phase1-L-Multi
- 特性:大规模(“L” 代表 Large)多语言(“Multi” 代表 Multilingual)数据集。
- 用途:
- 用于大规模自动评估,如图 4b(GPT-4 对标签准确性 / 相关性的评分)。
- 验证 TnT-LLM 框架在多语言场景下的泛化能力。
- 关键作用:通过大规模数据测试模型的效率和跨语言性能,弥补小规模数据集的局限性。
# (3)BingChat-Phase2-S-Eng
- 特性:小规模英文数据集,包含人类标注的标签(作为 “标准答案”)。
- 用途:
- 用于评估 “蒸馏轻量分类器” 的分类性能(与 GPT-4 直接分类对比),如 Table 3 中 “人类标注为基准” 的结果。
- 生成 GPT-4 与人类标注的混淆矩阵(图 7),分析标注分歧的具体类别(如意图标签的边界模糊问题)。
- 关键作用:验证轻量分类器是否符合人类对 “正确分类” 的判断,评估其在小规模高质量数据上的准确性。
# (4)BingChat-Phase2-L-Multi
- 特性:大规模多语言数据集,以 GPT-4 标注的标签作为 “标准答案”。
- 用途:
- 评估轻量分类器在大规模多语言场景下的性能,如 Table 3 中 “非英语对话” 的结果。
- 分析不同嵌入方法(ada2/Instructor-XL)在多语言文本上的适配性(如发现非英语文本性能低于英语)。
- 关键作用:验证模型在真实大规模多语言场景中的实用性,测试其效率和跨语言鲁棒性。
# 个人总结
本论文提出了一个成本低且性能较好的分类框架,逻辑简单,可行性较强,且论文发布时间是 2023 年,而现在有越来越多更强大的 LLM 出现,该框架的分类效果大概率也会有所提升。其主要就是充分地利用了 LLM 进行大规模工作,大大减少了人工数据量与研究量。
不过 100% 地利用 LLM 是否能做到最好最优的分类呢?他这个文章里用的对比组也还是和 LLM 相关的,没有用那种纯数学方法进行对比,这个问题还是有待商榷。