# Attention 注意力机制
注意力机制是一种 让模型在处理序列数据时 “有选择性地关注重要信息” 的技术,核心思想类似人类阅读时的注意力分配 —— 比如读 “小明给小红送了一本书,她很喜欢” 时,我们会自然聚焦 “她” 与 “小红” 的关联,而非平均关注每个词。
注意力机制通过计算 “关联权重” 实现对重要信息的聚焦,核心是三个向量的交互:
- Query(查询):当前位置的 “关注点”(比如 “她” 这个词,需要找到它指代的对象);
- Key(键):所有位置的 “信息标签”(比如 “小明”“小红”“书” 各自的特征);
- Value(值):所有位置的 “具体信息”(比如 “小红” 对应的语义内容)。
计算步骤:
- 计算 Query 与每个 Key 的 “相似度”(通常用点积或余弦相似度),得到 “原始权重”;
- 用 softmax 将原始权重归一化(转换为 0~1 的概率,总和为 1),得到 “注意力权重”(权重越高,说明该位置与当前 Query 越相关);
- 用注意力权重对 Value 进行加权求和,得到 “融合了关键信息的输出”。
- 自注意力(Self-Attention):Query、Key、Value 来自同一个序列(如一句话内部的词与词关联),用于捕捉序列内部的依赖关系(如 “她” 与 “小红” 的指代)。
# Transformer
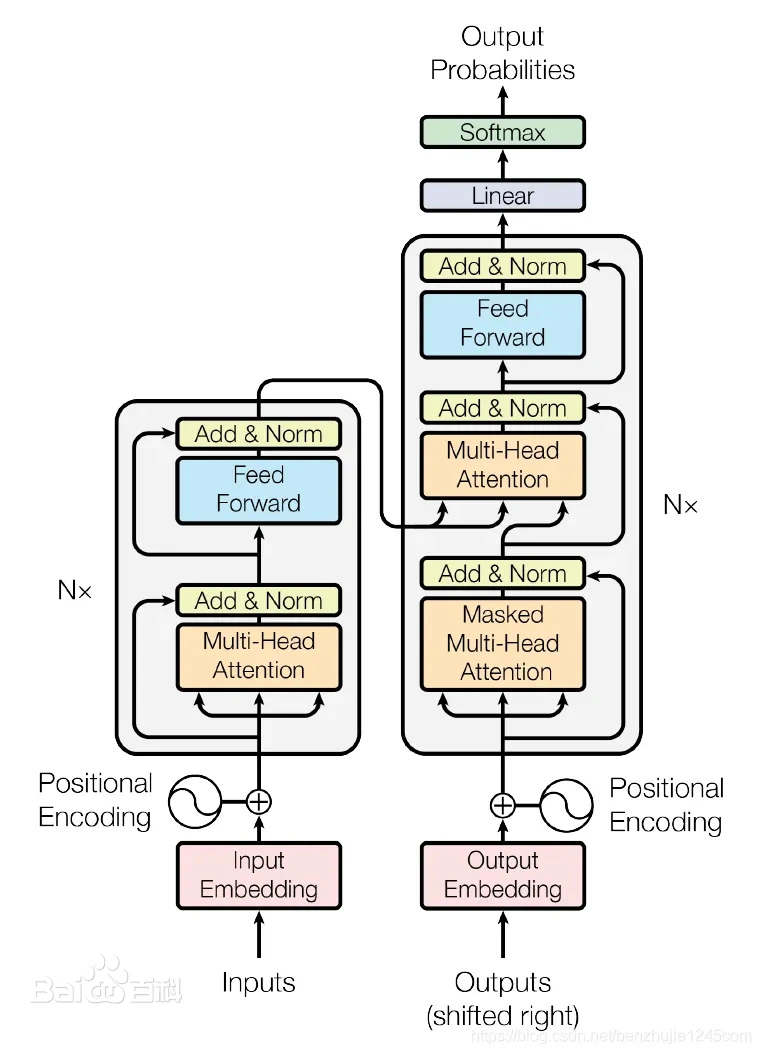
基于自注意力机制的序列建模架构
Transformer 的目标是:在并行处理序列的同时,高效捕捉序列中任意两个位置的依赖关系(无论距离远近)。
Transformer 由编码器(Encoder) 和解码器(Decoder) 两部分组成,整体结构如图所示(以机器翻译为例,输入为源语言句子,输出为目标语言句子):[输入序列] → 编码器 → [上下文特征] → 解码器 → [输出序列]
# 1. 编码器(Encoder):将输入序列转换为 “上下文感知的特征表示”
编码器由 N 个相同的 “编码器层” 堆叠而成(论文中 N=6),每个编码器层包含两个核心模块:
- 多头自注意力机制(Multi-Head Attention)
- 前馈神经网络(Feed-Forward Network)
且每个模块后都配有残差连接(Residual Connection) 和层归一化(Layer Normalization)。
# 2. 解码器(Decoder):根据编码器特征生成目标序列
解码器同样由 N 个相同的 “解码器层” 堆叠而成(N=6),每个解码器层包含三个模块:
- 掩码多头自注意力(Masked Multi-Head Attention)
- 编码器 - 解码器注意力(Encoder-Decoder Attention)
- 前馈神经网络(同编码器,带残差连接和层归一化)
# 影响
Transformer 彻底改变了 NLP 的研究范式:
- 基于 “仅编码器” 结构,衍生出 BERT、RoBERTa 等模型(擅长文本理解任务,如分类、问答);
- 基于 “仅解码器” 结构,衍生出 GPT 系列模型(擅长文本生成任务,如写作、翻译);
- 成为预训练语言模型的 “标准架构”,推动了 NLP 任务性能的跨越式提升。
很推荐观看 B 站上的这个视频:《Attention is all you need》论文解读及 Transformer 架构详细介绍